
.png)
על תופעות ה Double Descent וה-Grokking
- shlomoyona

- Apr 16
- 4 min read
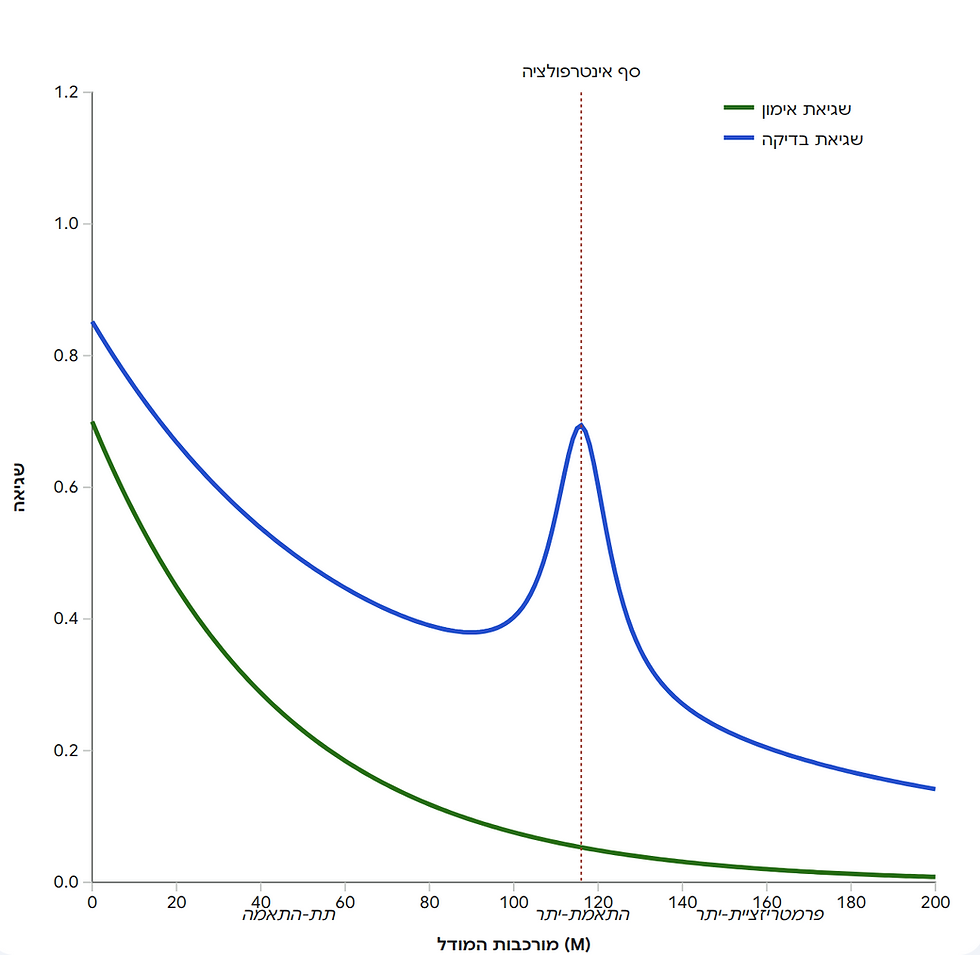
תופעת ה-Double Descent (או ה Model-wise Double Descent) היא תגלית מפתיעה, חשובה ומעניינת בלמידת מכונה מודרנית, והיא הפכה על פיה את מה שלימדו אותנו בסטטיסטיקה קלאסית. כדי להבין אותה, צריך קודם לחזור לפרדיגמה הישנה של הטרייד-אוף בין הטיה לבין שונות. בתאוריה הקלאסית, שגיאת המודל מתנהגת בצורת אות פרסה. אם המודל פשוט מדי, השגיאה גבוהה עקב תת-התאמה, מה שאנחנו מכירים כ-Underfitting. ככל שנגדיל את מורכבות המודל, השגיאה תרד עד לנקודה אופטימלית, ואז תתחיל לעלות שוב משום שהמודל מתחיל לשנן את הרעש שבנתונים, מצב המוכר כהתאמת-יתר, שאותה אנחנו מכירים בשם Overfitting. תופעת ה-Double Descent מתארת את מה שקורה כשממשיכים להגדיל את המודל הרבה מעבר לאותה נקודת קצה קלאסית.
מה קורה בתופעת ה-Double Descent?
התופעה מתחלקת למעשה לשלושה שלבים לאורך ציר מורכבות המודל. בשלב הראשון, באזור הקלאסי, אנו רואים את ההתנהגות המוכרת: ככל שמורכבות המודל עולה, שגיאת הבדיקה יורדת ואז מתחילה לטפס. השלב השני מתרחש בנקודה שמכונה, סף האינטרפולציה. זוהי הנקודה שבה המודל מורכב בדיוק במידה הנדרשת כדי להגיע לשגיאת אימון של אפס. במצב זה, המודל נדחק לפינה ונאלץ להתאים את עצמו באופן מדויק ונוקשה לרעש הקיים בנתונים, מה שמוביל לכך ששגיאת הבדיקה מגיעה לשיא שלילי וביצועי המודל על נתונים חדשים הם הגרועים ביותר.
ההפתעה הגדולה מגיעה בשלב השלישי, אזור פרמטריזציית-היתר. כשממשיכים להוסיף פרמטרים מעבר לסף האינטרפולציה, שגיאת הבדיקה מתחילה לרדת שוב באופן עקבי, ולרוב אף מגיעה לביצועים טובים מובהקים יותר מאשר בנקודת המינימום של האזור הקלאסי.
למה זה עובד?
ההסבר העמוק להצלחה של מודלים מרובי-פרמטרים קשור לגיאומטריה של מרחב הפתרונות ולרגולריזציה מרומזת, שמתבצעת על ידי אלגוריתמי האופטימיזציה. באזור של פרמטריזציית-יתר, כאשר ישנם לדוגמה פי מאה יותר פרמטרים מאשר דגימות אימון, נוצר מצב בו קיימים אינסוף פתרונות מתמטיים שונים שיכולים להביא את שגיאת האימון לאפס.
בתוך ים הפתרונות האפשריים הזה, אלגוריתמים כמו Stochastic Gradient Descent נוטים באופן טבעי ומתמטי למצוא את הפתרון החלק ביותר, או את זה בעל הנורמה המינימלית. במקום שהמודל ייאלץ להתעקם בצורה חדה ומלאכותית כדי לעבור דרך כל נקודת רעש בנתונים, ריבוי הפרמטרים מעניק לו שפע של דרגות חופש. דרגות חופש אלו מאפשרות לו להעביר עקומה חלקה ואלגנטית שגם משיגה שגיאת אימון אפס, וגם מצליחה להכליל בצורה יוצאת מן הכלל על נתונים חדשים שטרם ראה.
מה עושים עם זה ולמה זה טוב?
התופעה הזו מספקת למעשה את ההצדקה התאורטית לגישת חוקי קנה המידה ששולטת כיום בפיתוח ארכיטקטורות מתקדמות, כמו מודלי שפה ענקיים או מודלי מרחב מצב. ההבנה הזו שחררה את מפתחי ה-AI מהפחד לבנות מודלים עצומים עם מיליארדי פרמטרים, גם כאשר מאגרי המידע הזמינים מוגבלים יחסית. התובנה היא שאם נדחוף את המודל עמוק מספיק אל תוך אזור פרמטריזציית-היתר, נקטוף את פירות ההכללה הטובה יותר.
הגישה הרווחת כיום היא שעדיף לאמן מודל רחב ועמוק מאוד כדי ליהנות מהירידה השנייה ומהמיקומים הגיאומטריים האידאליים שהמודל מוצא, ולאחר מכן להפעיל עליו טכניקות קוונטיזציה ודחיסת משקולות. המודל הדחוס שומר על אותה הבנה חלקה של המרחב, ומאפשר הגשה חסכונית ויעילה בסביבות פרודקשן מבלי לאבד את היכולות הגבוהות שהושגו בזכות ממדיו המקוריים בשלב האימון.
אילו תופעות דומות קיימות?
תופעה דומה ומעניינת נוספת היא ה-Grokking, ה-הארה! בתופעה זו, המודל מגיע לשגיאת אימון אפס ונראה על פניו שהוא סובל מהתאמת-יתר מוחלטת, עם שגיאת בדיקה גבוהה מאוד. עם זאת, אם ממשיכים לאמן אותו פרק זמן ממושך, הרבה מעבר לנקודה שבה האימון נראה אבוד, שגיאת הבדיקה צונחת לפתע והמודל מתחיל להכליל באופן מושלם. ההבדל המרכזי הוא שבעוד Double Descent מתרחש כשמגדילים את כמות הפרמטרים, Grokking מתרחש לאורך ציר הזמן ומספר ה-Epochs. בשלבים הראשונים המודל בוחר לשנן את הנתונים כי זהו הפתרון הקל ביותר חישובית, ורק לאחר אופטימיזציה ארוכה הוא מאתר את הייצוג הפנימי האמיתי והמכליל שדורש נורמה נמוכה יותר.

תופעה קרובה נוספת היא Epoch-wise Double Descent, שבה הירידה הכפולה של שגיאת הבדיקה מתרחשת תוך כדי תהליך האימון עצמו ככל שמתקדמים במספר ה-Epochs, והיא תלויה בין היתר בגודל אצוות הנתונים ובקצב הלמידה. כאן השינוי הוא בזמן האימון. המודל קבוע, אמנם עם כמות עצומה של פרמטרים, אבל אנחנו מסתכלים על ציר ה-X כזמן, כמות ה-Epochs. השגיאה יורדת, עולה בגלל Overfitting זמני, ואז יורדת שוב ככל שממשיכים לאמן.


השווה והשונה בין Grokking לבין Epoch-wise Double Descent
ניתן לראות ב-Grokking וב-Epoch-wise Double Descent שני ביטויים של תהליך שבו המודל משנה את דעתו לגבי הדרך הנכונה לפתור את הבעיה. המשותף הבולט ביותר ביניהן הוא הדינמיקה הלא-מונוטונית של הלמידה: בשני המקרים, המודל מגיע למצב של טעות אפס באימון, אינטרפולציה, הרבה לפני שהוא מצליח להכליל לנתונים חדשים. בשלב הביניים הזה, נדמה שהמודל נמצא ב-Overfitting מוחלט, ורק המשך אימון ממושך, לעיתים הרבה מעבר למה שנחשב סביר בעבר, מוביל לשיפור הפתאומי והדרמטי בביצועים.
השוני העיקרי טמון בהקשר שבו התופעות מופיעות ובסיבה לדבשת בגרף השגיאה. תופעת ה- Epoch-wise Double Descent מזוהה לרוב עם מצבים שבהם יש רעש בנתונים ומורכבות המודל קרובה לסף האינטרפולציה. במצב זה, המודל לומד קודם את האות האמיתי, אחר כך מתאמץ ללמוד את הרעש, וזה מה שמעלה את השגיאה בבדיקה, ורק בסוף מצליח להחליק את הפתרון שוב. לעומת זאת, Grokking נצפה בעיקר במשימות אלגוריתמיות טהורות, כמו למידת לוח הכפל בקבוצות סופיות, והוא מתואר כמעבר איכותי בין אסטרטגיית שינון לבין אסטרטגיית הבנה/הכללה של חוקיות מתמטית.
הבדל נוסף נעוץ בתפקיד של הרגולריזציה והאופטימיזציה. ב-Grokking, דעיכת משקולות היא לרוב הכרחית כדי לדחוף את המודל לזנוח את פתרון השינון המורכב לטובת פתרון אלגוריתמי פשוט ורזה יותר. ב-Double Descent לעומת זאת, התופעה קשורה יותר למבנה של מרחב הפרמטרים ולנטייה הטבעית של אלגוריתמים כמו SGD למצוא פתרונות בעלי נורמה נמוכה במודלים רחבים מאוד. לסיכום, בעוד ש-Double Descent מתארת כיצד המודל מתמודד עם רעש, Grokking מתארת כיצד המודל מגלה מבנה לוגי חבוי.
המושגים החשובים
נקודת ה Sweet Spot היא הנקודה שבה ערך השגיאה בבדיקות הנמוך ביותר והמודל אינו ב Underfitting ואינו ב Overfitting. נקודת ה Interpolation Threshold היא הנקודה שבה מספר הפרמטרים שווה למספר הדוגמאות באימון. תחום ה Over Parametrization הוא התחום שבו שגיאת הבדיקה של המודל יורדת שוב בשל תופעת ה Model-wise Double Descent.

אנחנו ב- Mathematic.ai יודעים "להרים מכסה מנוע" במערכות לומדות, יודעים לתכנן ולבנות אותן מאפס, יודעים לשפר ולהאיץ אותן ויודעים להביא אותן לסקייל גבוה ולמצב בר-קיימא בפרודקשן. אנחנו מספקים שירותים של מחקר אלגוריתמי יישומי, מתודולוגיה של ניסויים, שיטות הערכה, אוטומציה של תהליכים.
דברו איתי:
שלמה יונה,
מייסד ומדען ראשי,
מתמטיקאי מחקר ופיתוח בע"מ
053-7326360
פודקאסט על החברה ועליי, שלמה יונה, ואופן העבודה שלנו ואיתנו:
Comments