
.png)
בעיית ה-Entity Resolution בבניית ה-Knowledge Graph
- shlomoyona

- 4 days ago
- 5 min read
רציתם לבנות בארגון גרף ידע מתוך המידע הארגוני שהגיע ממקורות שונים ובייצוגים שונים מזמנים שונים וברמות שונות של איכות התוכן. כדי לקחת את המידע הארגוני שאינו מובנה נשענים על הפעלת מודלי שפה גדולים כדי לחלץ ישויות וכדי לחלץ קשרים מתוך הטקסט.
אחת מהבעיות החמורות והנפוצות היא כפילות ישויות או היעדר זיקוק ישויות. מטבעם, מודלי שפה הם סטוכסטיים ומושפעים מההקשר המקומי של כל פסוקית טקסט. ולכן, כאשר ישות זהה בעולם האמיתי, למשל, פרויקט אסטרטגי, איש מפתח או רכיב תוכנה, מופיעה תחת שמות שונים במסמכים שונים, המודל נוטה לחלץ אותה כצמתים נפרדים ועצמאיים בגרף.
ההשלכות של הפיצולים הללו בגרף אינן רצויות ואף הרסניות לשימושים שרצינו מגרף הידע. במצב התקין, ישות מרכזית אמורה להוות צומת רכז בעל דרגת קישוריות גבוהה, שמאפשר לאלגוריתמים של סריקת הגרף לנווט דרכו ביעילות. כאשר הישות מפוצלת לעשרות צמתים שונים ובלתי מקושרים, צפיפות הגרף המקומית צונחת, ומסלולי ההסקה הלוגיים נקטעים.
כאשר מערכת הסוכנים נדרשת לענות על שאילתה חוצת-ארגון, מנגנון השליפה, בין אם הוא מבוסס על חיפוש שכנים או על Multi-hop, ייכשל באיסוף התמונה המלאה משום שחלק ניכר מהמידע מקושר לווריאציות שמיות שלא אותרו. הסוכן החכם, שמקבל לידיו תת-גרף חסר ומקוטע, יתקשה לבצע Grounding אמין. בניסיון להשלים את פערי המידע ולעמוד בדרישת המשתמש להפיק תשובה רציפה, הסוכן נוטה ברמות סבירות גבוהות להזות עובדות או להמציא קשרים שאינם קיימים באמת. יתרה מזאת, הפתרון הנאיבי של השוואת כל צומת חדש לכלל הצמתים שקיימים במערכת כדי למצוא כפילויות מוביל לסיבוכיות זמן ריצה של O(n²), סיבוכיות בעייתית לגרף בעל כמות צמתים רבה.
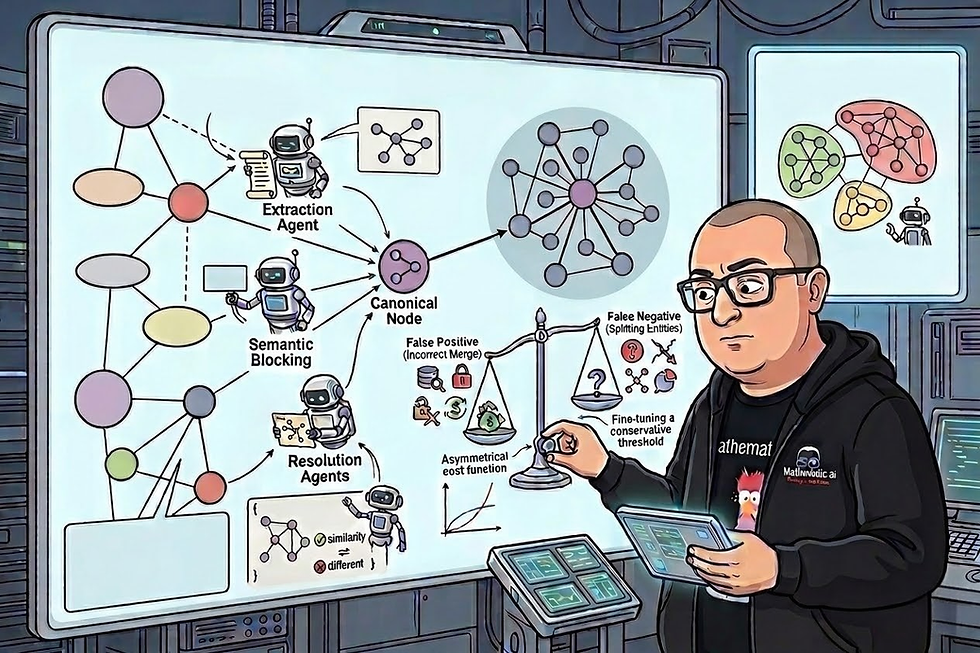
אז מה פתרון בית הספר לבעיה הנפוצה הזאת? פתרון בית הספר לבעיית פיצול הישויות בגרף ידע מבוסס על ארכיטקטורת Multi-Agent שמשלבת לוגיקה דטרמיניסטית עם הבנה סמנטית עמוקה. ברמת ה-High Level, המערכת פועלת כפס ייצור מבוקר שמפריד בין שלב חילוץ הישויות הגולמי לבין שלב יישוב הישויות והמיזוג הטופולוגי. תהליך זה מנוהל באמצעות State Graph Orchestration, שמבטיח שכל ישות חדשה עוברת סדרת בדיקות בטרם הטמעתה בגרף, ובכך נמנעים מצניחת צפיפות הגרף וקיטוע מסלולי ההסקה הלוגיים.
ברמת ה-Low Level, התהליך מתחיל בסוכן חילוץ ונרמול שמפעיל אלגוריתמי מרחק מחרוזות כגון Levenshtein או Jaro-Winkler. ספרייה מומלצת לשימוש היא RapidFuzz שמתבססת על אלגוריתמים למחרק בין מחרוזות בשילוב יוריסטיקות שימושיות נוספות והאצה משמעותית במימוש. שלב זה מצמצם את מרחב הבעיה על ידי איחוד מיידי של וריאציות כתיב טריוויאליות ללא שימוש במשאבי חישוב יקרים. לאחר מכן, המערכת מיישמת מנגנון Semantic Blocking לפתרון בעיית הסיבוכיות החישובית. במקום השוואה מלאה של כל צומת לכלל הגרף, התכונות החיוניות של הישות מומרות לוקטורים צפופים שמאוחסנים באינדקס מסוג HNSW. אלגוריתמי קיבוץ מרחביים כמו DBSCAN תוחמים את הישויות לאשכולות סמנטיים קטנים ומתקבל זמן החיפוש ליניארי שמאפשר עבודה עם מסדי נתונים רחבי היקף.
בשלב הבא, Resolution Agent שמבוסס על מודל שפה חזק מקבל לידיו את זוגות הישויות החשודות ככפילויות יחד עם ייצוג JSON של השכונה הגרפית שלהן. הסוכן אינו מסתמך רק על דמיון שמי, אלא מנתח את הטופולוגיה הגרפית כדי לזהות אם ישויות בעלות שמות שונים חולקות קשתות משותפות לאותם אובייקטים בארגון. כדי להבטיח את אמינות התהליך, Reflection Agent מבצע בקרה נוספת למניעת סתירות לוגיות בטרם ביצוע המיזוג הסופי.
המימוש ההנדסי של המיזוג מחייב עבודה עם Canonical Forms לשמירה על Data Lineage. כאשר מתקבלת החלטה על איחוד, המערכת מייצרת צומת קנוני חדש המאגד את כלל התכונות והקשתות, בעוד הצמתים המקוריים נשמרים כצמתי Alias המקושרים לצומת המאוחד בקשר מסוג IS_ALIAS_OF. ארכיטקטורה זו מבטיחה עקביות מלאה בבסיס הנתונים ומאפשרת יכולת חזרה לאחור במקרה של זיהוי שגוי, תוך שהיא מספקת לסוכני השליפה תמונה מלאה ורציפה של המידע הארגוני.
ביקורת על פתרון בית הספר
פתרון בית ספר הוא אינו בהכרח הטוב ביותר או היעיל ביותר אלא משהו שנותן מענה סביר בזמן קצר יחסית ומעשי. טוב שנהיה מודעים גם לביקורות. עבור חלק מהביקורות יש גם הצעות:
הפעלת מודלי שפה גדולים וסוכני בקרה על כל זוג ישויות חשוד גוררת תקורה חישובית עצומה. גישה זו מייצרת צוואר בקבוק של שיהוי ועלויות עיבוד. בתכנון מערכות רחבות היקף עדיף להחליף את רוב עבודת סוכני השפה בסיווג על ידי מודלים קלים וייעודיים, שמספקים רמת דיוק קרובה בשבריר ממשאבי החישוב. לא חייבים LLM, אפשר להסתפק גם ב-MLM ואם לא אז בגרסה מקומית קטנה יותר עם פחות פרמטרים.
השימוש באלגוריתמים מבוססי מרחק עריכה, הממומשים בספריות תוכנה מהירות, יעיל לשפות בעלות מורפולוגיה פשוטה, אך נוטה לייצר רעש רב ולפספס הקשרים בשפות בעלות מורפולוגיה עשירה כמו עברית, במיוחד ללא שימוש במנתח מורפולוגי מקדים שיודע להתמודד עם טקסט חסר ניקוד. בנוסף, שלב החסימה הסמנטית שמסתמך על אינדקס HNSW ואלגוריתם DBSCAN מציג אתגרים משמעותיים. אלגוריתם HNSW מתבסס על חילוץ שכנים מקורב שמטבעו מכניס שגיאות מסוג false negative כבר בתחילת הצינור. כמו כן, אלגוריתם DBSCAN מתקשה מאוד להתמודד עם אשכולות בעלי צפיפות משתנה, תופעה שכיחה במרחבי שיכון וקטוריים של ישויות טקסטואליות. אז היכן שלא סוברים ש RapidFuzz ודומיו יעשו את העבודה, השתמשו בטרנספורמר שעבר fine tuning לצרכים שלכם או כל אסטרטגיה מתחרה אחרת. לגבי חסרונות אלגוריתמיים, אם אתם בקיאים בחומר ויודעים לנתח משמעויות ולחפש חלופות, מעולה, אחרת, דברו איתנו ב- Mathematic.ai ונעזור לכם עם ההיבטים האלגוריתמיים, המשמעויות והחלופות שמתאימות לצרכים שלכם ולמקרים שלכם כרגע ובהמשך.
במערכות שמטפלות במיליוני מסמכים רגישים, שגיאת false positive היא חמורה ועלולה לגרום לזליגת הרשאות וכשלים כמו למשל, חיבור שגוי של נתונים פיננסיים. פונקציית העלות חייבת להטיל קנס אסימטרי כבד מאוד על מיזוג שגוי בהשוואה להשארת ישויות מפוצלות. המשמעות ההנדסית היא תכנון ספי החלטה שמרניים במיוחד עבור סוכני ההכרעה.
למה לא לבצע זיקוק זהויות עם אלגוריתם למציאת קהילות בגרפים?
איך הפתרון הזה שונה מדברים שדיברנו עליהם בפוסטים קודמים כמו שימוש באלגוריתמים למציאת קהילות בגרפים כמו לוביין ו-ליידן?
ההבדל המהותי בין הארכיטקטורה המאוחדת לבין אלגוריתמים דוגמת לוביין או ליידן טמון בייעוד התפקודי ובנקודת הזמן של ההפעלה. אלגוריתמי לוביין וליידן הם כלי ניתוח מבניים שנועדו לזיהוי קהילות על בסיס צפיפות קשתות בגרף קיים. הם פועלים בגישת אופליין ומנסים למקסם מדדי מודולריות כדי למצוא קבוצות הדוקות של צמתים. לעומת זאת, פתרון בית הספר המאוחד מבצע רזולוציית זהות בשיטת In-line, כלומר בזמן אמת כחלק מתהליך בניית הגרף, במטרה למנוע את היווצרות הפיצולים מראש ולא רק לזהות אותם לאחר מעשה.
ברמה האלגוריתמית, לוביין וליידן נשענים על טופולוגיה קיימת ואינם מסוגלים לזהות זהות בין שני צמתים מבודדים שאינם מקושרים ביניהם פיזית. בבעיה שתוארה, שבה ישויות זהות מופיעות תחת שמות שונים במסמכים שונים, מודל השפה יוצר צמתים מנותקים שביניהם אין קשתות כלל. במצב כזה, אלגוריתמי זיהוי קהילות לא יזהו קשר בין הישויות. הארכיטקטורה המאוחדת פותרת זאת באמצעות שימוש באינדקסים וקטוריים שמאפשרים למצוא דמיון סמנטי גם בהיעדר קשרים גרפיים, ובכך היא מקשרת בין איים מבודדים של מידע שאלגוריתם מבני פשוט יחמיץ.
הבדל קריטי נוסף הוא רמת הדיוק והיכולת לבצע הכרעה מהותית. לוביין וליידן הם אלגוריתמים סטטיסטיים שיכולים להצביע על כך שצמתים שייכים לאותו אשכול, אך הם אינם מבינים את המשמעות של הישות. הם עשויים לקבץ יחד את פרויקט אוריון ואת מנהל הפרויקט בשל הקישוריות ביניהם, אך הם לעולם לא יקבעו ששני צמתים הם למעשה אותו פרויקט. פתרון המולטי אג'נט המאוחד משתמש בסוכן החלטה בעל הבנה לוגית המנתח את מאפייני הישות וההקשר שלה, מה שמאפשר לבצע מיזוג טופולוגי מדויק ולא רק שיוך לקבוצה.
לסיום
ולסיום, שאלה מקצועית למחשבה: ביישום מנגנון רזולוציית ישויות אוטומטי על מערך נתונים של מיליוני מסמכים רגישים, כיצד תתכננו את פונקציית העלות של המערכת שמאזנת בין זיהוי חיובי כוזב (False Positive, מיזוג שגוי של שתי ישויות נפרדות, שעלול להוביל לזליגת הרשאות מידע וחיבור נתונים פיננסיים שגויים לסוכן) לבין זיהוי שלילי כוזב (False Negative, השארת הישויות מפוצלות, שתוביל להסקה חסרה ולפגיעה בחוויית המשתמש), וכיצד החלטה זו תשפיע על ארכיטקטורת ניהול התצורה ומדיניות ה-Rollback בבסיס הנתונים?
צריכים עזרה עם AI/GenAI/AgenticAI/AI Platform ועם מעבר מהוכחת יכולת לעבודה בסקייל מלא באנטרפרייז?
זקוקים לשותף טכנולוגי עתיר ניסיון שיודע לספק שירותי מחקר ופיתוח Hands-on, מארגוני אנטרפרייז ועד סטארט-אפים, על מנת להוציא חזון אלגוריתמי שלכם מהכוח אל הפועל?
רוצים מחקר אלגוריתמי יישומי?
הבה נדבר!
שלמה יונה,
מייסד ומדען ראשי,
מתמטיקאי מחקר ופיתוח בע"מ
053-7326360
פודקאסט על החברה ועליי, שלמה יונה, ואופן העבודה שלנו ואיתנו:
Comments